
Virtual Scientists for Real Infrastructure
2026-03-19
The digital twin community has been shaped by a metaphor that has unduly constrained the community's thinking. The idea comes from David Gelernter's Mirror Worlds (1991), which imagined software models reflecting the state of real-world systems — hospitals, cities, power grids — in real time. The concept itself, however, is traced back to Michael Grieves' work at the University of Michigan and then John Vickers at NASA. But it is Gelernter's image that has stuck.
In the previous two posts in this series, I've argued that genuine scientific understanding requires more than observation. It requires the integration of three capacities:
- the ability to explore an environment and detect regularities,
- the ability to invent explanatory concepts that account for those regularities, and
- the ability to test predictions derived from those concepts against further experience.
Galileo's inclined plane experiments were the case study (Post 1); the complementarity of world models and large language models (LLMs) was the contemporary application (Post 2). The second post ended by asking what kind of architecture integrates both. The answer is not a mirror, but a laboratory with a scientist in it. That is what an agentic digital twin is, or can be. And that is the focus of this third post.
From mirrors to laboratories
The mirror metaphor has led many astray. Much of what is marketed today as a "digital twin" is more accurately described as a digital shadow — a one-way data flow from a physical system to a computational model, used for monitoring and visualisation. The shadow receives data but has no capacity to act back on the system. It observes, but it does not intervene.
A genuine digital twin is something more. The definition increasingly adopted by the research community requires bidirectional interaction, so that a digital twin is dynamically updated with data from its physical counterpart, has predictive capability, and informs decisions that realise value.
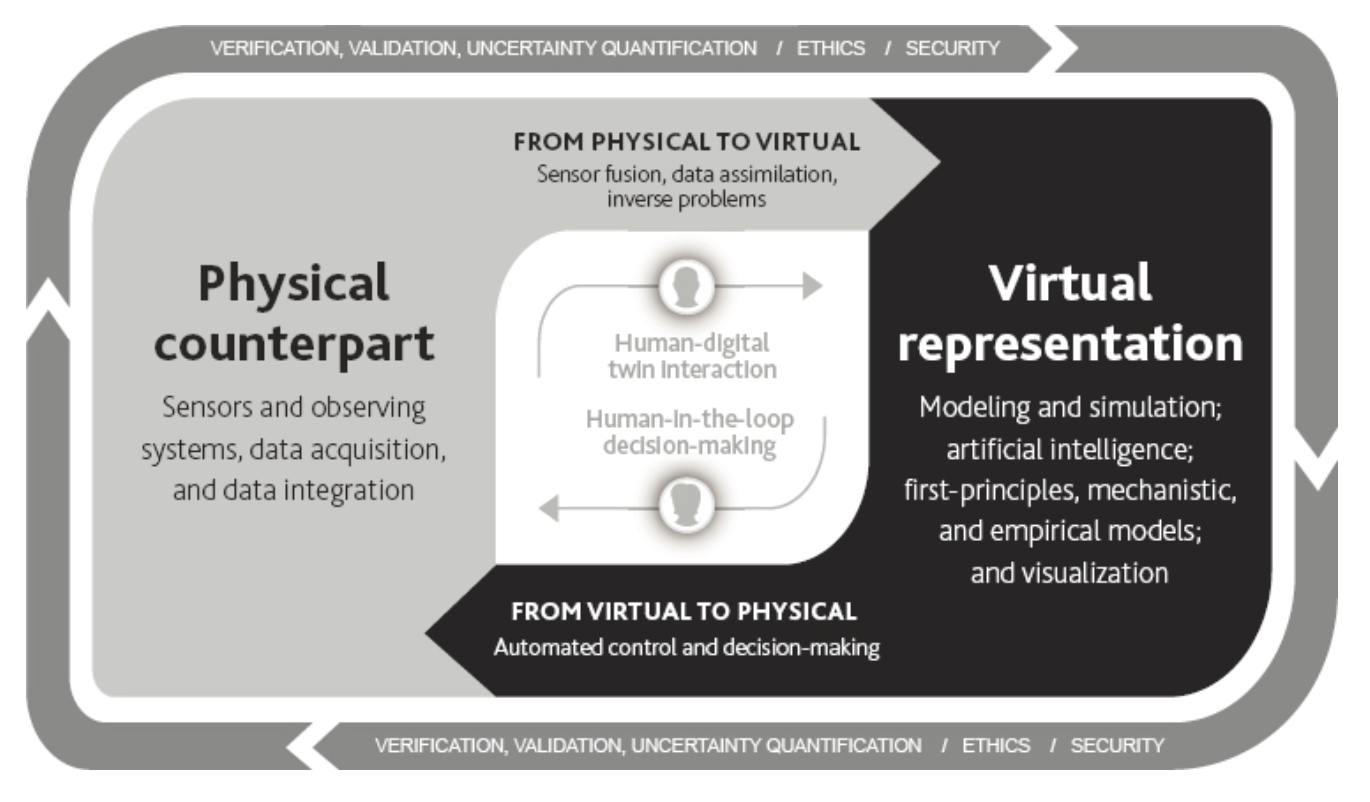
But even a true digital twin, with its bidirectional loop, is not yet a laboratory. The loop may be present, but the reasoning within it can vary enormously. A digital twin that feeds back optimised setpoints based on a fixed model is closing the loop, but it isn't doing science. So what happens when you enrich the reasoning capacity within that loop? When the system can not only predict and control, but hypothesise, experiment, and learn?
That is what makes a digital twin agentic. And the tighter the loop, the more powerful the reasoning becomes.
In a recent paper, my co-authors and I proposed a taxonomy of agentic digital twins that treats coupling as one of three fundamental dimensions, alongside the locus of agency and model evolution. Rather than reproduce the full taxonomy here, I want to focus on what it reveals when read through the lens of Galileo's scientific reasoning.
As Figure 1 shows, at the loose end we have something close to the conventional mirror. Data is sampled periodically, updates flow in batches, and the twin's relationship to the physical system is arm's-length. Loose coupling can support monitoring and retrospective analysis—Galileo's exploration phase—but little else. The twin can detect patterns, but it can't test hypotheses because it has no way to intervene.
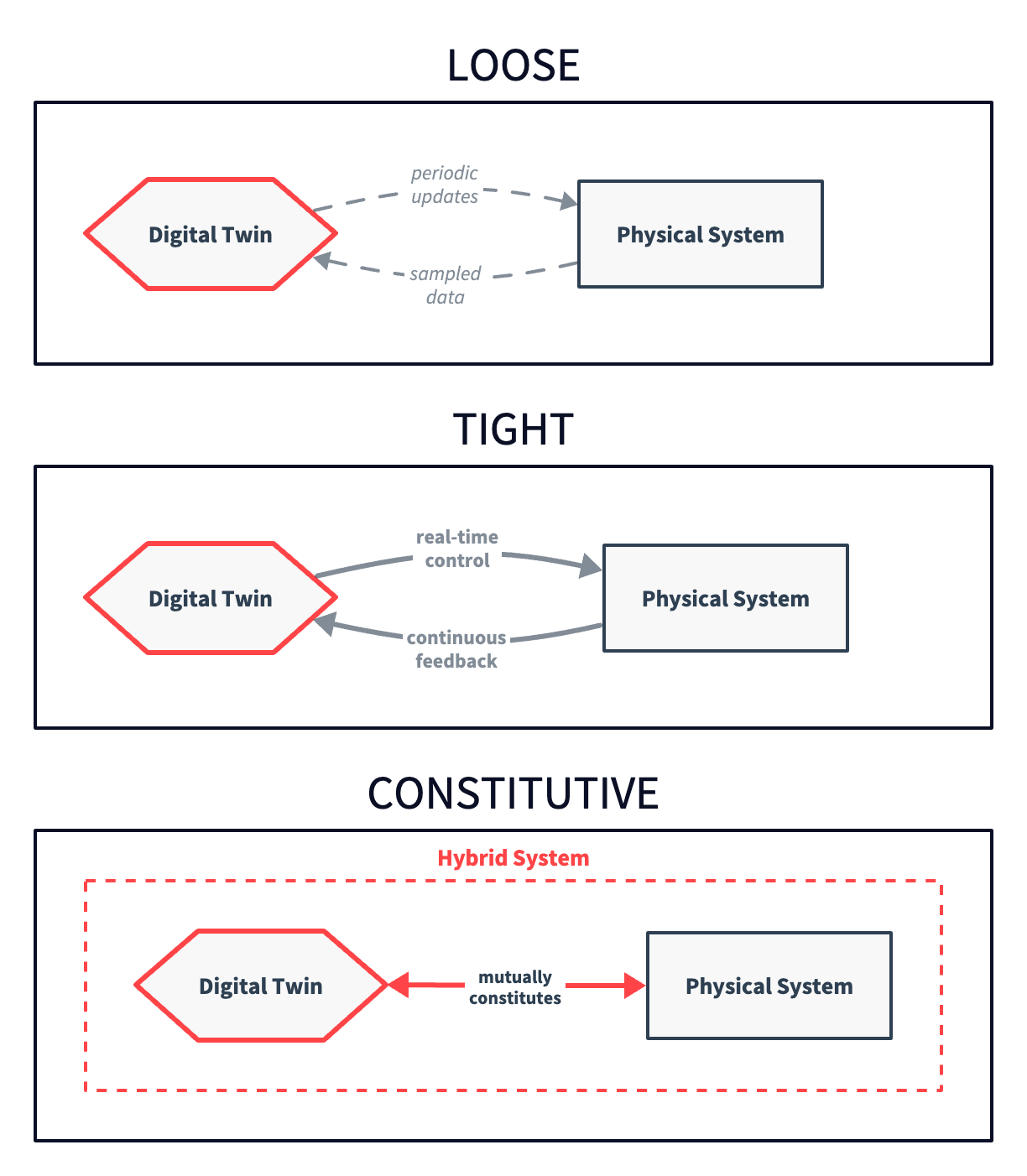
Tightly coupled systems are where the twin and physical system are connected in real time (or with sufficiently high frequency). Continuous feedback flows in both directions (i.e. the twin sends control signals, the system responds, and the twin observes the response and adjusts). Such a regime enables experimentation. For instance, the twin can derive a prediction ("if I adjust the valve pressure by 5%, flow rate should increase by 12%"), execute it, measure the result, and learn from the discrepancy. Tight loops like this are what support and justify abductive leaps like Galileos' "doveria esser" (ought to be).
Finally, at the constitutive end, the twin and the physical system become mutually constitutive. The twin doesn't just model the system but participates in defining what the system is as a technical object amenable to measurement and control. The boundary between representation and reality becomes porous. The twin's categories (i.e. what it measures, what it optimises, what it treats as a variable) actively shape the system it purports to represent.
Now, the digital twin is no longer a mirror but a system where the acts of measurement and representation are inseparable from the constitution of the phenomena being measured. This goes beyond existing digital twin taxonomies, which typically treat coupling as a matter of data flow frequency rather than ontological entanglement — and it is, we acknowledge, the most speculative element of our framework.
Agency and model evolution
Coupling determines whether the system can close the perception-action loop, and whether it has a laboratory. But two further questions remain: who is doing the reasoning within that laboratory, and how deep can the learning go?
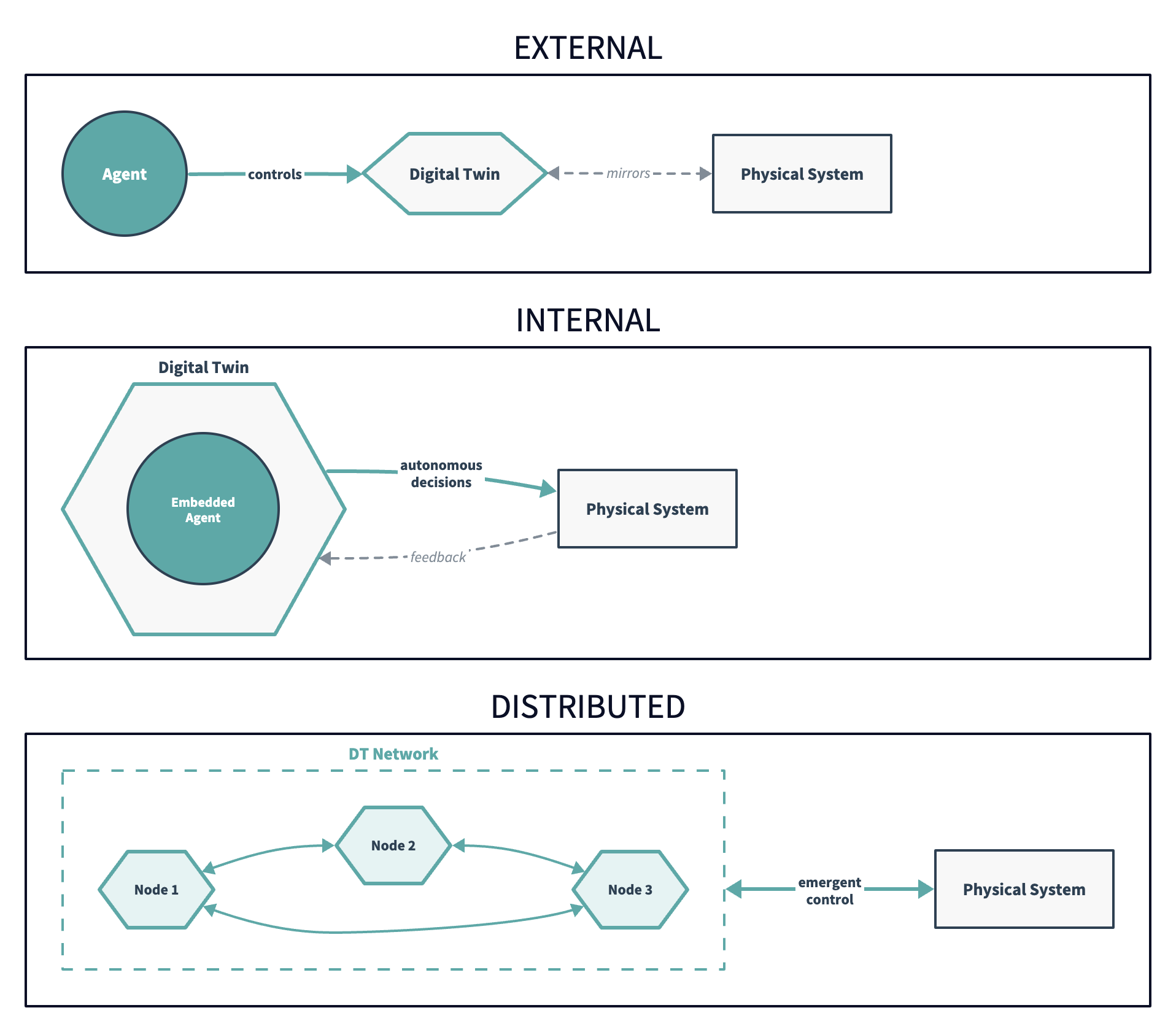
Agency (Figure 2) determines who or what is doing the reasoning within that laboratory. In the simplest case from our taxonomy, the agency is external — a human operator uses the twin as a tool, much as Galileo used his inclined plane. The twin provides the environment, but the human does the cognitive labour and provides the hypotheses. In more advanced configurations, agency is internal (e.g. an AI system embedded within the twin that can autonomously generate hypotheses, design experiments, and interpret results). And in the most advanced (and speculative) configurations, agency is distributed. That is, it emerges from the interaction between multiple twins in a network, with no single locus of control.
Model evolution determines the depth of learning the system can achieve. This is where Susan Carey's distinction from Post 2 connects.
A static twin has fixed parameters ( = fixed in Figure 3). It makes predictions based on an unchanging model, which is useful for well-understood systems where the physics doesn't change, but would be incapable of learning. An adaptive twin updates its parameters in response to feedback — this is Carey's enrichment (see Post 2). The twin gets better at predicting within a fixed representational vocabulary (e.g. it can learn that the acceleration on this particular incline is 3.2 m/s² rather than 3.0, but it can't invent the concept of acceleration itself).
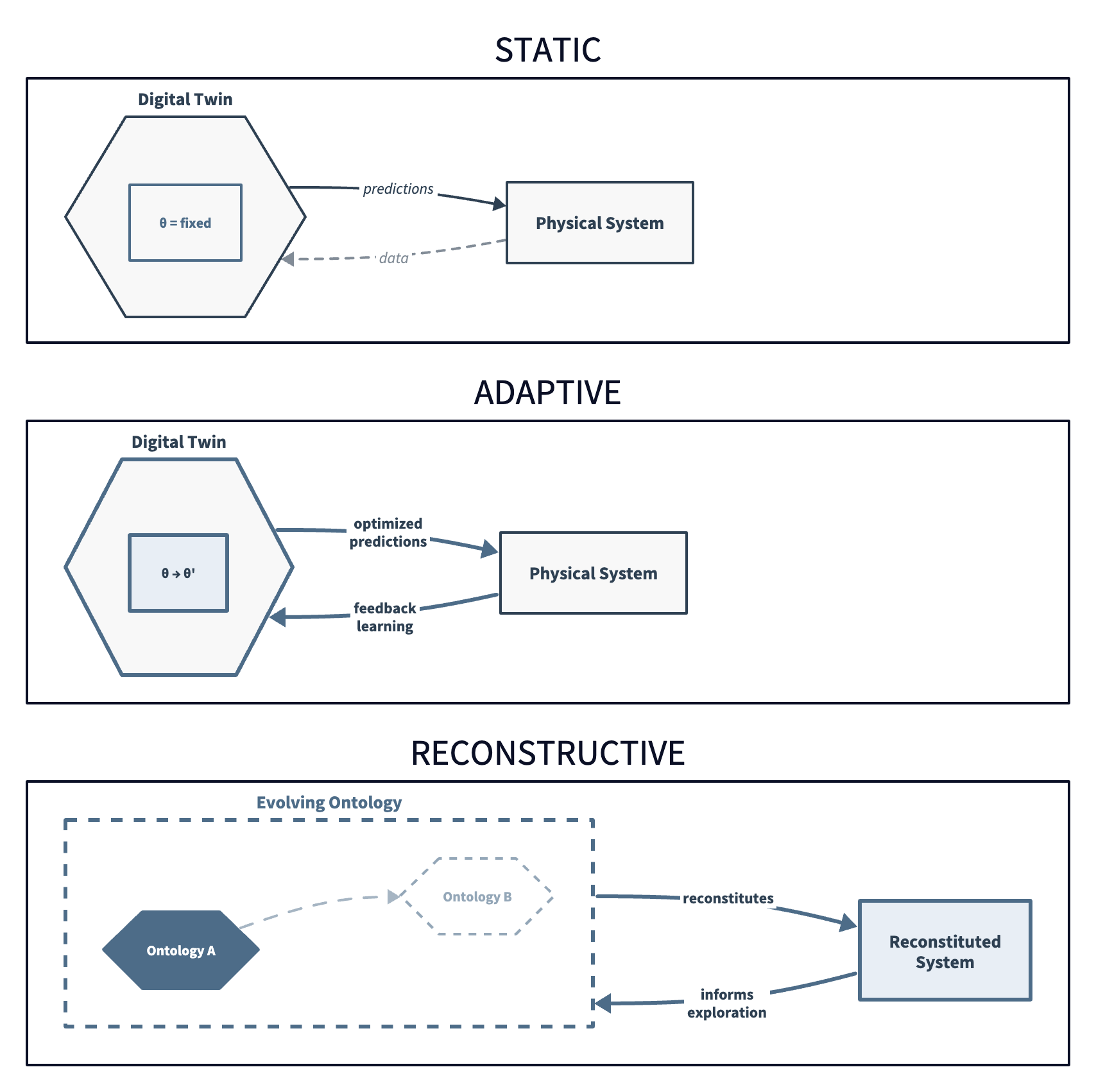
A reconstructive twin can restructure its own representational categories. It can move from Ontology A to Ontology B (Carey's radical conceptual change), and it is the computational analogue of Galileo's deepest move.
Whether any current system can genuinely do this is an open question we hope to explore. But it is also precisely where the integration of world models and LLM-type reasoning is expected to become essential. The world model provides the laboratory in which hypotheses are tested. The LLM-type reasoning provides the capacity to generate new representational categories (or new ontologies) when the existing ones fail. Reconstructive model evolution is what you get when both capacities are present and tightly coupled.
What this looks like in practice
The speculative nature of our taxonomy could give the impression that it is just abstract conceptual engineering or a mere philosophical thought experiment. This would be an understandable reaction but also a mistake.
The UK's critical national infrastructure presents immediate, concrete opportunities (and urgent needs) for agentic digital twins operating at various points in the taxonomy.
Consider energy balancing. The National Energy System Operator manages a grid that is increasingly volatile (e.g. variable renewables, distributed generation, demand-side response). The Gemini Principles and the Apollo Protocol have already laid the policy groundwork for cross-sector digital twins in UK infrastructure. An agentic digital twin of the grid would maintain a real-time model of energy flows, generation capacity, and demand patterns. At the adaptive level, it could update its predictions as conditions change. At the tight coupling level, it could execute bounded interventions (e.g. adjusting balancing mechanisms, redistributing load) and observe the results. Each intervention would be an experiment, and each discrepancy between prediction and outcome would help refine the model.
Or consider water networks. UK water infrastructure loses around three billion litres per day to leakage. An agentic digital twin of a water network wouldn't just monitor pressure data, it could hypothesise about where leaks are developing based on patterns of pressure loss, test those hypotheses by adjusting flow, and learn from the results. The coupling here would be critical. A loosely coupled twin would tell you where leakage was worst last month, but a tightly coupled twin can identify an emerging leak and act before it becomes a burst.
In each case, the agentic digital twin is doing what we've been describing throughout this series. It is exploring a structured environment, generating explanatory hypotheses, testing predictions, and learning from the discrepancies. It is becoming a virtual scientist.
What's at stake
The agentic digital twin framework, as I've presented it here, offers a unifying lens for much of the current debate about AI's future. The "world model" that LeCun and others are pursuing is the agentic twin's internal representation of its target system (i.e. the laboratory). The "LLM-type reasoning" that makes language models effective at abduction is the scientist's capacity to generate and evaluate explanatory hypotheses. And the coupling between them is what grounds the reasoning in reality and prevents hallucination.
This is not a minor reframing. It suggests that world model researchers, LLM developers, and digital twin engineers are converging toward a common set of architectural requirements, even if their methods, data, and immediate objectives differ. The taxonomy we've proposed provides one map for navigating that unified space, showing where current systems sit, what capabilities emerge as you move through it, and where the genuinely novel possibilities (and risks) lie.
Those risks are very real, and have so far been overlooked in this series. They sharpen as we move toward the reconstructive frontier. An agentic digital twin that can restructure its own representational categories is one whose reasoning may become epistemically inscrutable, and begin operating with concepts that don't map onto anything in our vocabulary. How do you assure a system whose framework for understanding the world is one it generated for itself?
That question is the subject of my final post.
← Previous: World Models Need Scientists Too
Next in this series: Governing the Laboratory →